
最近,在维护 KProxy(一个代理服务,Web 版的 charles) 时,遇到一个故障问题:一个请求的响应早已结束,但是在一段时间后却触发了 request timeout。
1. 问题描述
KProxy server 作为代理服务,收到用户请求时会向真实服务端(real server)发出的一个 HTTP 请求,实现代理。但是,在真实服务端响应结束之后(过了较长一段时间),这个 KProxy 中的该请求的 timeout 事件却被触发了。由于真实服务端的响应早已结束,预期是不会触发 KProxy 请求侧的超时的。结合 KProxy 这边的一些超时保障逻辑,就出现了误“封禁”的问题。
核心情况,简单来说就是:一个请求的响应早已结束,但是在一段时间后却触发了 request timeout。
2. 代码复现
KProxy 相关的完整代码比较多,下面重写了一份简版,用以复现问题。
server.js 是一个简单的服务端,监听 8088 端口,对于请求会响应一串”1”,2 秒后完成响应:
1 | // file: server.js |
client.js 则会请求该服务:
1 | // file: client.js |
启动 server.js,然后执行 client.js,会看到控制台输出以下内容:

可以看到,当时间来到第 5 秒时,timeout 事件触发了。而实际情况是,服务端在 2 秒的时候就已经调用 .end 方法结束响应了。
查看 TCP 连接情况,看到连接也一致没有销毁。

3. 如何修复
修复方式很简单,可以在回调里添加 res.on('data', () =%&-g-t% {}) 这样一行代码:
1 | const http = require('http'); |
看下输出结果:

不会再误触发 timeout 事件。连接也正常销毁了。
但这一段看似无意义的代码(监听了 data 事件但其实什么事情也没有做),是如何”修复“这个问题的呢?
4. 背后的原因
下面结合 Node.js v16.10.0 的源码,来解释一下这个问题产生的原因。
4.1. http.request 的大致实现
为了更好理解这个问题,先简单介绍一些和 http.request 相关的知识。
调用 http.request 实际会创建一个 http ClientRequest 对象。而 ClientRequest 类是继承自 OutgoingMessage 类的,它是一个 Stream。所以我们可以通过 Stream 的 API 向请求体中不断写入信息,并且通过调用 .end 方法表示请求写入完成,例如:
1 | const http = require('http'); |
请求体发送完毕后,下一阶段就是等待处理响应数据。在响应头处理完毕后,Node.js 会创建 IncomingMessage 对象,这个对象也是一个 Stream(准确来说是继承自 Readable Stream )。然后调用 parser.onIncoming 方法:
1 | function parserOnHeadersComplete(versionMajor, versionMinor, headers, method, |
对于 ClientRequest 来说,parser.onIncoming 实际就是 parserOnIncomingClient 方法,它会触发 response 事件:
1 | function parserOnIncomingClient(res, shouldKeepAlive) { |
由于 ClientRequest 在创建时就会监听 response 事件来触发 http.request 的回调,因此在 http.request 的回调中或者 response 事件中都可以拿到 response 对象(IncomingMessage)。也就是说,回调触发的时候,响应头已经解析完毕,开始解析响应体。
涉及到的主要的类的大致关系如下:
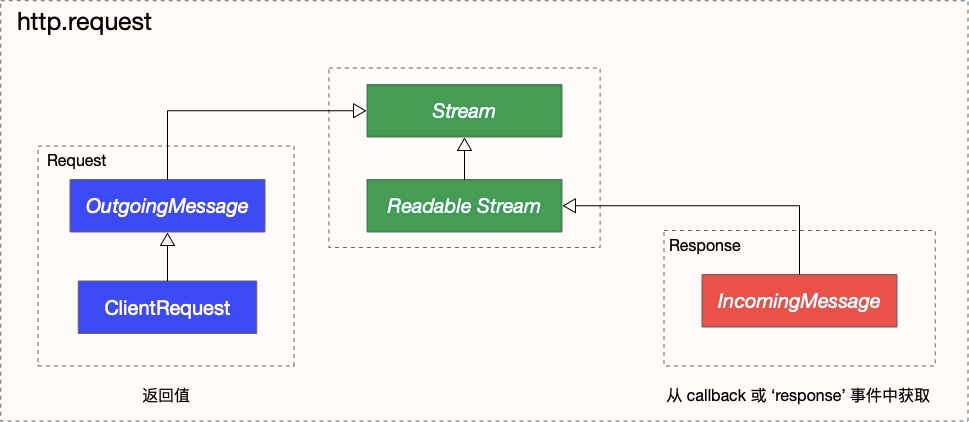
所以如果想拿到响应体的信息,可以在回调里监听对应 data 事件。
1 | const http = require('http'); |
4.2. Request Timeout 的实现
http.request 在超时的实现上,并没有什么非常特别之外,就是通过 JS Timer 来设置一个定时器:如果到期未被清理,则会触发 timeout 事件。设置定时器最后会调用到 stream_base_common.js 中的 setStreamTimeout 方法:
1 | function setStreamTimeout(msecs, callback) { |
this._onTimeout 则会触发 timeout 事件。
而我们更关注的是定期器的清除。因为请求超时的误触发,很可能会和没有成功清理定时器有关。那么,定时器何时会被清除呢?
当 socket 销毁时,定时器就会被清除:
1 | Socket.prototype._destroy = function(exception, cb) { |
对此,我们可以添加 NODE_DEBUG 环境变量来查看调试信息,使用下面命令启动我们修复后的代码(添加 data 空监听函数的):
1 | NODE_DEBUG=net node request.js 2%&-g-t%&1 %&-g-t%/dev/null | grep 'ms\|destroy' |
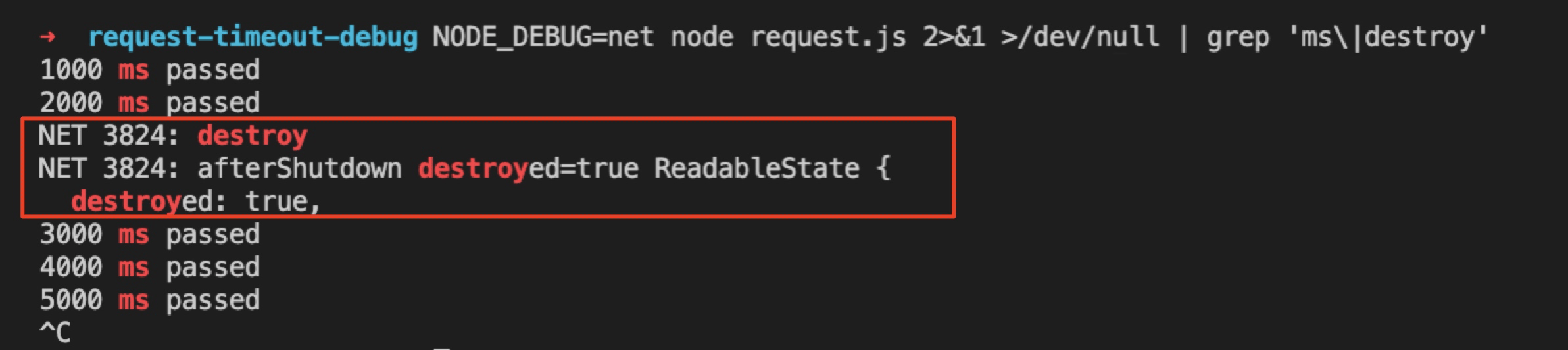
可以看到,正常调用了 Socket.prototype._destroy 方法。
去掉 res.on('data', () =%&-g-t% {}) 这行修复代码再试一下:

可以看到,一直都不会触发 destroy。
4.3. IncomingMessage 与 Socket
定时器清除的逻辑和 Socket 对象相关,但我们的修复代码操作的是 IncomingMessage 对象,那么他们之间有什么关系呢?
Socket 类继承自 Duplex(读写流),在流结束后会调用上面的 Socket.prototype._destroy 方法。
在实际接收响应时,C++ 层的 node_http_parser
1 | int on_body(const char* at, size_t length) { |
会把解析的响应体内容传到 JS 层的方法里,最终调用 parserOnBody 方法:
1 | function parserOnBody(b, start, len) { |
上面的 this.incoming 就是我们的 IncomingMessage 对象。其中主要的一段逻辑是
1 | const ret = stream.push(slice); |
它会向 IncomingMessage 中添加新的数据,如果返回值为 false,则会调用 readStop 方法。该方法会将 socket 流暂停:
1 | function readStop(socket) { |
两者在这块会有一个联系了。
4.4. Stream 的机制
根据上面的实现,可以知道:向 IncomingMessage 流添加数据时如果返回 false,则会暂停 Socket 流。下面结合 Stream 本身的机制,来看下是如何影响到超时定时器的清除的。
首先,是关于 .push 的返回值。
Stream 会有水位控制(highWaterMark),如果一个可读流被不断 push 进数据,但是没有被消费,这时候 Stream 会把这些数据“暂存”在内部,等待消费。显然,如果无限制存储数据,就可能出现内存问题,所以 Node.js 通过返回 false,来建议用户不要再继续写入了。
其次,是关于暂停流。
可读流如果被暂停,除了内部的暂停状态被置为 true 之外,还有一个改变是它的消费模式(reading mode)将会从 flowing mode 变为 pause mode:
1 | Readable.prototype.pause = function() { |
它们的一大区别就是暂停模式下,’data’ 监听不会收到事件,需要手动调用 stream 的 .read 方法来读取数据。
所以,大致原因就是,在我们没有消费 IncomingMessage 的情况下,由于响应体过大,超过最高水位线后,Node.js 就把 Socket 流暂停了,导致无法触发 Socket 的结束销毁,间接导致控制超时的定时器没有被销毁。
5. 再谈如何修复
5.1. 方法一
本文最开始,我们通过添加一段看似毫无意义的代码:
1 | res.on('data', () =%&-g-t% {}); |
解决了这个问题。到这里我们应该理解为什么这段修复代码有效。当然,还有其他两个情况下,该问题也不会发生。
5.2. 方法二
第二个是不给 http.request 添加 callback。例如把 client.js 代码变为:
1 | const http = require('http'); |
可以看到,这种情况下并未触发 timeout。
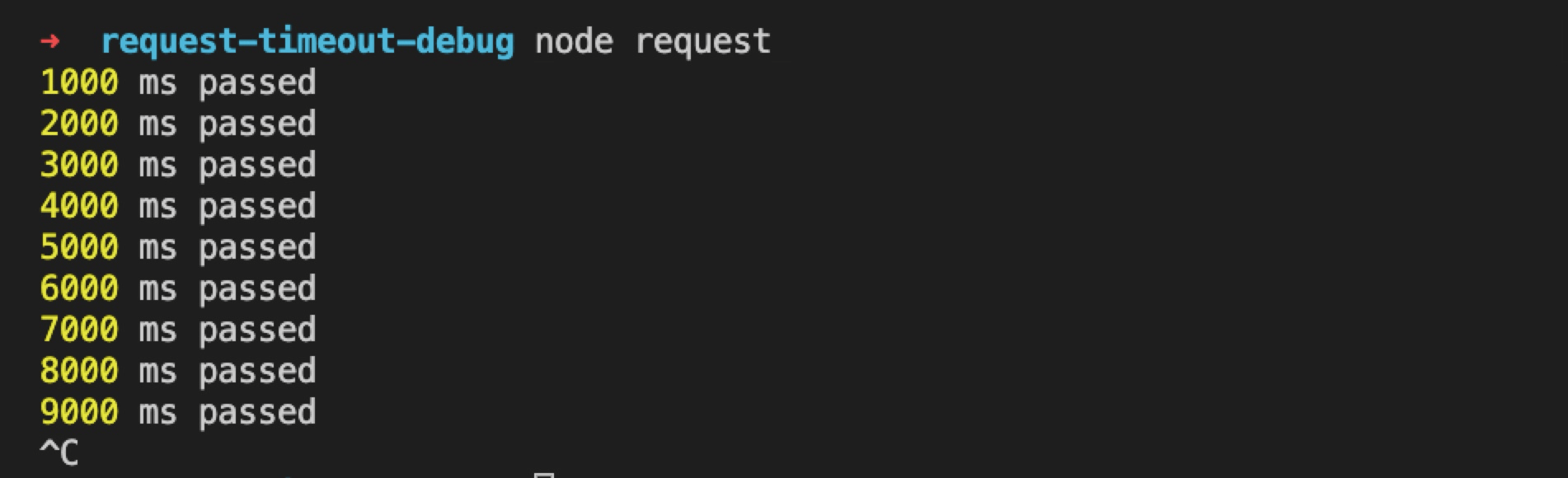
这是因为我们如果不添加回调(同时也不监听 response 事件),IncomingMessage 就会进入 dumped 状态:
1 | // If the user did not listen for the 'response' event, then they |
这个状态下,便不会再向 IncomingMessage push 数据,也就没有了后面的事儿。
5.3. 方法三
第三个方式是让服务端不要返回超过 16KB 的响应体。当然这从实际需求来说不太可行,但从原理上来说可以规避这个问题。
因为 highWaterMark 的默认值就是 16KB:
1 | function getDefaultHighWaterMark(objectMode) { |
我们可以尝试把 server.js 中的返回值长度减小一些:
1 | const http = require('http'); |
这样也不再会误触超时问题。
6. 详细的故障场景
KProxy 是怎么触发这个问题的呢?
作为代理服务器,KProxy 大致工作方式如下:
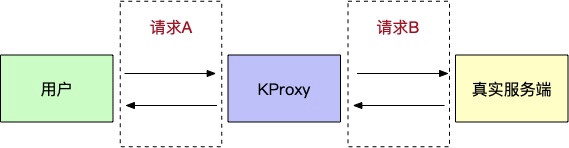
它在收到用户的请求时(请求 A),会通过 http.request 创建一个到真实服务端的连接(请求 B),将请求 A 的 OngoingMessage pipe 给请求 B,然后将请求 B 的 IncomingMessage pipe 给请求 A。
这个方式本身没有问题,但在一个特殊的功能下,会出现问题。
KProxy 可以支持完全覆盖响应体,在这种情况下,KProxy 会将请求 B 的响应头和用户设置的响应体直接拼接,形成完整的响应内容 pipe 给请求 A。可以看到,这里主要的区别就是,不会消费响应体(IncomingMessage)。但它仍然监听了 http.request 的回调。同时,由于该代理请求的响应体正好超过了 16KB,就导致了「请求理论上应该结束,但却“误报”超时」的问题。
7. 最后
由于本文结合源码阐述了该问题的原因,并且介绍了一些相关的基础知识,所以篇幅较长。精简来说:
- http 模块中,
IncomingMessage的写入状态会影响 Socket 流的启停状态,从而可能导致 Socket 流无法如期调用其destroy方法。 - 如果不关心响应信息,可以不要添加回调或 response 监听,否则可能由于触及 highWaterMark 而导致上面的情况,甚至引起一些内存问题
此外,再补充一点与该故障无关也相关的点,Readable Stream 如果没有被消费,不会触发 end 事件。所以下面的代码也是不会打印 ‘finish’ 的。
1 | const http = require('http'); |
除非也给它加上 res.on('data', () =%&-g-t% {}) 这段代码。
评论